Modeling using Decision Trees
The Neural Networks notebook can be found here.
The NN Interpretation notebook can be found here.
After exploring various kind of interpretable models, we turn to the dark side and fit a powerful Neural Network using Keras to learn as much as we can from the data, and then use its predictions to draw inferences.
Neural Network basic model
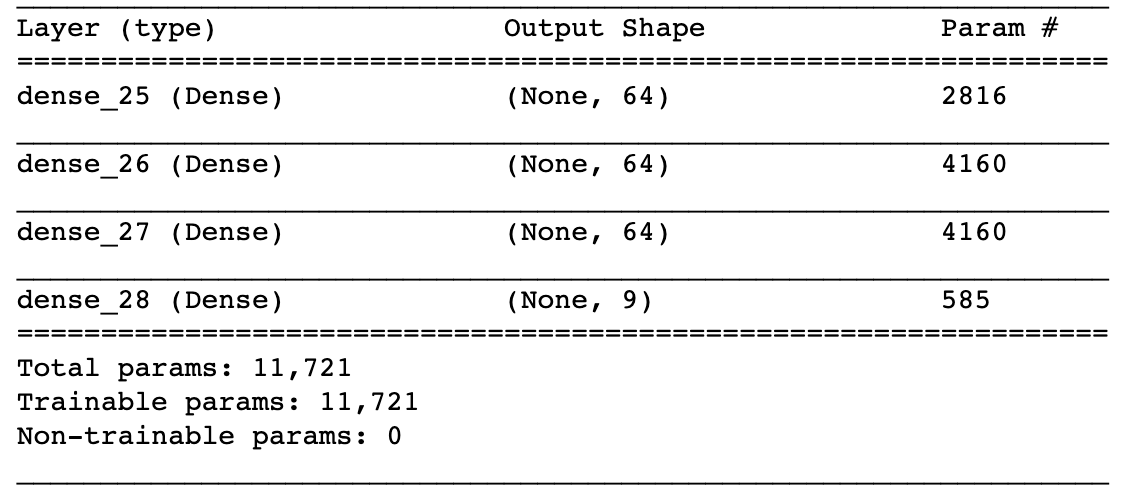
We start with a simple 3-layer fully connected Neural Network with 64 nodes per layer, with relu activation and a simple SGD optimizer. At the end we use a softmax layer to output probabilities. Our loss function is the classic categorical_entropy.
-
The only real improvement we make is weighting the classes based on the number of occourrences of each class to account for unbalances in the Crime dataset.
-
Also, remember to use the scaled version of the dataset, as Neural Networks are sensitive to variation in magnitude between features.
-
Training for 10 epochs and a batch size of 32 is enough for close to optimal performance, for a super-fast training time of 3 mins.
- Performance: excellent on the training set (0.6482 weighted AUC), poor on the test set (0.4981 wAUC, worse than chance).
Add one Dropout layer to reduce overfitting
Seeing as our first model dramatically overfitted to the training set, we decide to add a Dropout layer to make it more robust.
-
We also increase the number of fully connected layers to 4 and the size of each to 256 units.
-
We also change the activation to the slightly better LeakyRelu, and the optimizer to adam.
- Performance: again excellent on the training set (wAUC of 0.6459), this time exellent on the test set too, with minimal overfitting (wAUC of 0.6377). The respective accuracies are 0.3108 and 0.3070 for training, test.
Larger overnight model
Having found a somewhat sensible configuration, we enlarge and enhance it for a final model to be trained overnight for maximum performance. We add the following tweaks:
-
L1 and L2 regularization, for both bias and weights. Parameters (1e-6 and 1e-5 respectively) found by manual CV search.
-
Nadam optimizer
-
Also record top-5 accuracy for the model
-
100 epochs, for a training time of several hours
Unfortunately, the model ends up overfitting at the end, so the full training time is kind of wasted. But it still performs very well.
Interpretability
Neural Networks are often criticised for being hard to interpret, in the sense that the weights are learned by an iterative process and the large size of the layers makes it hard to directly compare differences in inputs to difference in outputs.
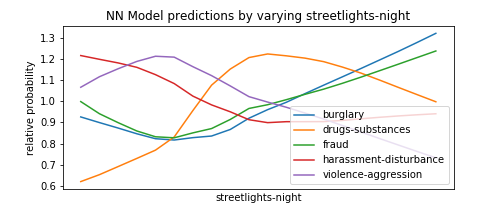
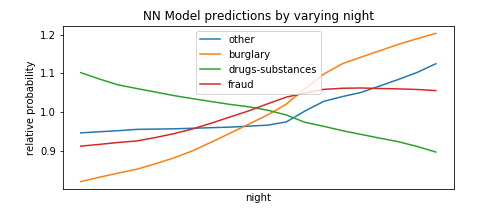
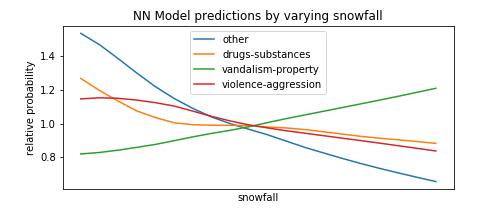
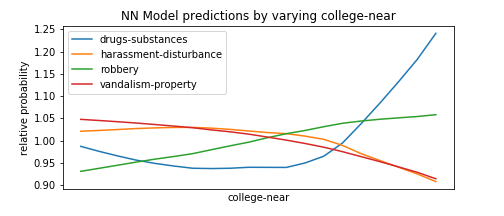
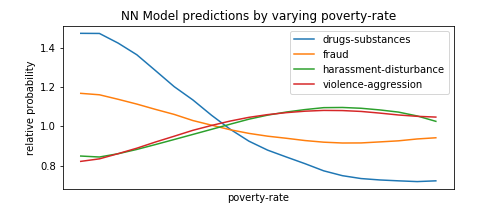
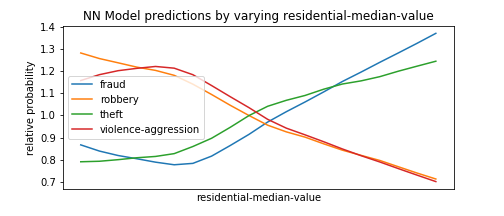
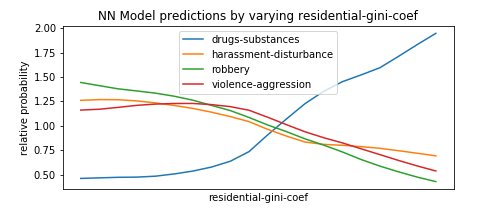
To this extent, we perform a technique similar to HW7, in which we form fake test instances with all predictors set to the median, and then vary one of the predictors to see how types of crime become more or less likely as that predictor goes from its minimum to its maximum value. We select the types of crimes with the most variance to avoid unnecessarily cluttering the plots with types that do not change much as the predictor varies.
Of course, this is not a complete exploration of the model’s behavior, as it also takes into account non-linear relationship between different features, and setting everything to the mean is not representative of the data in which many predictors are correlated, etc. but it’s a useful first-order approximation and many of the findings below make intuitive sense which is nice.