BaseData Utilities Python Library¶
This is a utilities library for Python-based data analysis, in which I attempt to encapsulate repeatable data cleansing workflows within a number of classes, methods, and helper functions focused on performing repeatable and predictable data transformations.
Note
Because this library is still a largely exploratory effort, there is a high probability that maintenance of this project will be abandoned in the near future.

GitHub repo: https://github.com/sedelmeyer/basedata
Documentation: https://sedelmeyer.github.io/basedata
Contents
Summary¶
This is an installable Python utilities library containing the following modules:
- basedata.ops
A number of classes and functions supporting the
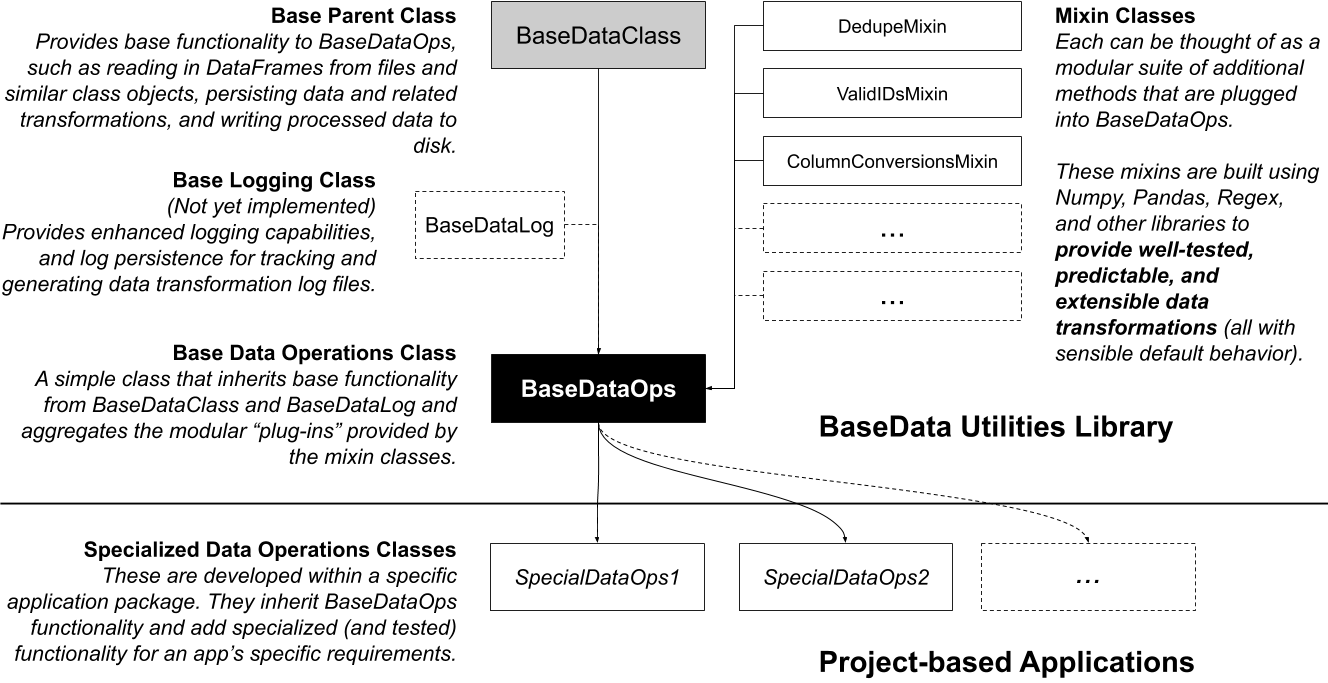
BaseDataOpsclass.This class packages a number of methods focused on performing repeatable and predictable data transformations, built upon
numpy,pandas,re, and other Python libraries.See the diagram below for a high-level summary of how this module and the
BaseDataOpsclass is structured.
- basedata.inventory
(Currently under development) Class methods for generating data and file inventory lists and tables.
- basedata.log
(Not yet implemented) Class methods for enhanced logging capabilities for recording and saving plain text data transformation log files.
This library is written using Python 3.6 and is tested against all Python versions >=3.5.
Installation¶
If you are using Pipenv to manage your dependencies and virtual environments, you can add the following to your Pipfile packages section (you can decide whether you want the package to be editable or not) and run pipenv update:
...
[packages]
...
basedata = {editable = true,git = "https://github.com/sedelmeyer/basedata"}
...
If you are using pure pip for installing the library, the equivalent command to what I have shown above is:
pip install -e git+https://github.com/sedelmeyer/basedata
If you are using conda environments you can likewise invoke pip from within your virtual environment to install directly from the GitHub repo. This can be accomplished either (a) directly from the command line after activating your environment, or (b) as a dependency specified in your conda environment.yml file as shown below:
name: ...
channels: ...
dependencies:
- ...
- pip
- pip:
- -e git+https://github.com/sedelmeyer/basedata
- ...
Basic Usage¶
The documentation for this library is still under development. Modules, functions, and classes already contained in this library all currently have extensive docstrings describing their behavior. Those docstrings can be easily viewed within the documentation.
The use of the BaseDataOps class, which is currently the most complete of all features contained in this library, follows this basic pattern…
# Import the BaseDataOps from the appropriate basedata module
from basedata.ops import BaseDataOps
# Invoke the BaseDataOps class by reading in a dataframe from file
Base = BaseDataOps.from_file("test_datafile.csv")
# Or, optionally, the class can be invoked by reading in a pandas.DataFrame
# object directly
Base = BaseDataOps.from_object(dataframe)
# The resulting dataframe persists in the BaseDataOps class object as self.df.
# Therefore, if you'd like to access the dataframe directly...
df_copy = Base.df
# Likewise, as transformations are performed using the BaseDataOps class
# instance, those changes are performed on the self.df object directly.
Base.drop_dupes(column=column_name, index_list=list_items, validate=True)
# The modified dataframe can also be saved to .csv directly via the BaseDataOps
# class instance.
Base.to_file("target_filename.csv")
For more detailed review of available class methods, behaviors, and associated parameters, please see the docstrings and source code located within the src/basedata directory.

